Inleiding tot Data Science
Contents
All data has its beauty, but not everyone sees it
—Damian Mingle
Inleiding tot Data Science#
In dit eerste deel van de cursus Data Science 1, wordt verduidelijkt wat Data Science in grote lijnen omvat.
In de inleiding worden een aantal elementen uit de doeken gedaan die relevant en essentieel zijn om inzicht te kunnen verwerven is het vakgebied Data Science.
In het tweede deel (Data Science Processes) worden een paar gebruikelijke aanpakken van Data Science projecten weergegeven en verduidelijkt.
De laatste twee delen bestaan elk uit een raamwerk waarbinnen methoden, technieken en hulpmiddelen -nodig om Data Science projecten tot een goed eind te kunnen brengen- worden gepositioneerd. Dit raamwerk dient ter ondersteuning om de volgende delen van de cursus beter te kunnen plaatsten en situeren in het uitgebreide en omvangrijke vakgebied Data Science.
Wie meer wil weten over Data Science, kan in de bibliografie de verwijzingen vinden van een aantal recente boeken over het onderwerp.
Data Science - Inleiding#
Wat is data?#
Data science draait rond het werken met en het analyseren van data (of in het Nederlands: gegevens).
Data kan gedefinieerd worden als informatie in ruwe of ongeorganiseerde vorm die verwijst naar (of is een weergave van) objecten, ideeën of condities.
Iedereen, en elke organisatie, instelling, bedrijf beschikt over data en kan niet functioneren zonder. Negen van de tien topmanagers zien data als de vierde productiefactor, net zo belangrijk voor een onderneming als land, arbeid en kapitaal. Bovendien vindt twee derde van de ondervraagde topmanagers hun eigen organisatie ‘data driven’, dat betekent dat het verzamelen en analyseren van data aan de basis ligt van hun bedrijfsstrategie en van de dagelijkse besluitvorming. Dit blijkt uit het internationale onderzoek naar het gebruik van big data in zakelijke besluitvorming door de Economist Intelligence Unit, in opdracht van Capgemini (The Deciding Factor: Big Data & Decision making – 2012).
Maar data is een nogal ruim begrip. Voordat we het domein van data science kunnen verkennen, dienen we wat meer over data, de verschillende vormen en de eigenschappen ervan te weten.
Klassieke opdeling van data#
In de praktijk onderscheidt men verschillende types van data, komende van allerlei diverse bronnen in uiteenlopende vormen. Om enige vorm van overzicht te bekomen, wordt data in een bedrijfscontext regelmatig op verschillende manieren ingedeeld. Hierbij enkele voorbeelden:
Voorbeeld 1: Indeling op basis van het datatype. Hierbij onderscheidt men:
Master data is data die niet vaak verandert en wordt door de business steeds op dezelfde manier gebruikt ( bijvoorbeeld: klantnummer, leveringsadres van een bepaalde klant,…);
Transactionele data verandert voortdurend en betreft dagdagelijks businessactiviteiten. Dit soort data beschrijft een gebeurtenis (bijvoorbeeld: bestellingen, aankoopbonnen, …);
Analytische data is data over de performantie van de business ((bijvoorbeeld: marktaandeel, solvabiliteitsratio’s, …);


Fig. 1 Transactionele data, analytische data en master data#
Voorbeeld 2: Indeling op basis van waarvoor de data binnen het bedrijf gebruikt wordt: financiële data, * voorraadbeheer data*, aankoop data, verkoop data, leveranciersbeheer data, klantenbeheer data, payroll data,…


Fig. 2 Indeling op basis van datagebruik binnen het bedrijf#
Voorbeeld 3: de aard en manier van opslaan van de data:
Gestructureerde data is sterk georganiseerde data die volgens een voorgedefinieerd data model (meestal in een matrix vorm bestaande uit rijen en kolommen) wordt opgeslagen. Is op een eenvoudige manier toegankelijk en kan gemakkelijk, zonder veel bijkomende inspanningen gebruikt worden in analyses (bijvoorbeeld: data opgeslagen in relationele databanken).
Ongestructureerde data is niet opgeslagen volgens een voorgedefinieerd data model en wordt op een onsamenhangende en verspreide manier bijgehouden. Ze is moeilijk toegankelijk en vereist bijkomende preprocessing vooraleer het kan gebruikt worden in analysis (bijvoorbeeld: data opgeslagen in meeting verslagen, rapporten, e-mails,..).


Fig. 3 Gestructureerde data versus ongestructureerde data#
Men kan heel wat ramingen vinden betreffende het percentage van de data binnen bedrijven dat ongestructureerde data is. Afhankelijk van bron (voornamelijk gespecialiseerde firma’s zoals IBM, SAS, Gartner, TechRepublic, The Computer World magazine, …) varieert het geraamde percentage tussen 75% en 85%.
Andere, nieuwere opdeling van data#
Naast de klassieke manieren om data op te delen, bestaan er ook een aantal alternatieve manieren. Hier volgend een paar voorbeelden.
Voorbeeld 1: Indeling op basis van het doel van de data output (purpose data output):
‘Schema-then-capture’-data: hierbij wordt eerst bepaald welke data men nodig heeft voor een analyse om vervolgens deze data te gaan verzamelen.
‘Capture-first-ask-questions-later’-data: hierbij wordt data verzameld om achteraf te kijken welke vragen/analyses men met deze data zou kunnen beantwoorden.


Fig. 4 https://www.codeproject.com/articles/700324/data-protection-and-privacy-law-for-developers#
Voorbeeld 2: Streaming data, versus static data
Voorbeeld 3:
Attitudinal data weerspiegelen het belang dat een klant hecht aan bepaalde eigenschappen van aangeboden producten en diensten (Hoe voelt een klant zich?).
Behavioural data omvat o.a. het koopgedrag en merkvoorkeur van consumenten, en wordt gebruikt om promotiecampagne uit te werken (Wat doet een klant?).
Demographic data is data die sociaaleconomisch van aard is, zoals bijvoorbeeld populatie, ras, inkomen, onderwijs en werkgelegenheid, die specifieke geografische locaties vertegenwoordigen en vaak geassocieerd is met de tijd (Wie is de klant?)
Big data#
Wanneer over Data Science wordt gesproken, wordt zeer snel de link gelegd met ‘big data’. Het is een feit dat het besef om data op een verantwoorde en correcte manier te analyseren gegroeid is naar mate o.a. de beschikbaarheid van data en de volumes van data zijn toegenomen, maar Data Science heeft een langere voorgeschiedenis dan ‘big data’.
De term ‘big data’ wordt gebruikt sinds de jaren 1990 en verwees oorspronkelijk naar datasets met een omvang die buiten het vermogen vallen van veelgebruikte software tools om deze binnen een aanvaardbaar tijdsbestek in te lezen, te beheren en/of te verwerken.
Later –geïntroduceerd in een Gartner rapport in 2001- werd het 3V-model gehanteerd om ‘big data’ te omschrijven. ‘Big data’ dient aan minstens 2 van de volgende 3 eigenschappen te voldoen:
een hoge data velocity (= de snelheid waaraan data gegenereerd, gecapteerd en/of afgeleverd wordt)
een groot volume
een grote variety (diversiteit, data komt van vele verschillende bronnen en zit in meerdere databanken in niet uniforme vormen)


Fig. 5 3V-model#
Een groot volume volstaat dus niet om een dataset als ‘big data’ te bestempelen.
Tegenwoordig wordt aan het 3V-model (Velocity, Volume en Variety) voor ‘big data’ nog twee bijkomende dimensies ( Variability en Veracity) toegevoegd:
een uitgesproken variability (= verschillende bronnen kunnen elkaar tegenspreken en het geheel extra compliceren)
een veranderlijke veracity (= waarheidsgetrouwheid, de kwaliteit van de data kan van bron tot bron sterk variëren)
De essentie van wat ‘big data’ is, komt neer op het feit dat gewone of gebruikelijke dataverwerking er niet op toegepast kan worden.
Merk op dat bepaalde datasets die op basis van de standaarden van vandaag als ‘big data’ beschouwd worden, morgen, door de technologische evoluties, niet meer als ‘big data’ gezien zullen worden.
Smart data#
Data is niet altijd valide, kan onvolledig zijn, kan inconsistenties bevatten, er kan ruis op zitten (fouten, outliers, …), enz.
De selectie (o.a. capteren, verzamelen), opkuisen/zuiveren (o.a. verifiëren, valideren, corrigeren), verwerking ( classificeren, transformeren) en voorbereiding (o.a. in juist formaat zetten) van data om te komen tot smart data is arbeids- en tijdsintensief.


Fig. 6 Big data versus Smart data#
De selectie zorgt voor relevante data, het opkuisen/zuiveren zorgt voor correcte data, het verwerken en voorbereiden zorgt voor computer verwerkbare data.
Meetschalen of meetniveaus#
In de praktijk komt zowel het vaststellen van de aan- of afwezigheid als de mate van de aanwezigheid van een bepaalde eigenschap of kenmerk van een object, voorwerp, persoon, … neer op meten. Heel wat data komt dan ook overeen met metingen. Het meten van een eigenschap of kenmerk heeft natuurlijk pas zin wanneer er verschillende waarden kunnen vastgesteld worden. Wanneer men een eigenschap meet, wordt in principe een waarde toegekend als weerspiegeling van de mate waarin de eigenschap aanwezig is. Deze waarde kan een omschrijving zijn (vb een film krijgt in een tijdschrift de beoordeling zeer slecht, slecht, matig, goed of zeer goed) of een getal (vb score van een student op het examen van het vak Data Science).
Data die een weergave is van metingen die niet in een getal, maar wel in een categorie-omschrijving worden uitgedrukt, noemt men kwalitatieve data. Voorbeelden zijn het geslacht van een persoon, het merk van een auto, …
Data die een weergave is van metingen die wel in een getal worden uitgedrukt, noemt men kwantitatieve data. Voorbeelden zijn temperatuur, leeftijd, afstand, …
De verschillende meetschalen#
Een eigenschap kan op 4 verschillende meetniveaus, ook wel meetschalen genoemd, gemeten worden.
Een meetniveau of meetschaal wordt gedefinieerd aan de hand van de aan- of afwezigheid van vier ** karakteristieken**:
Een meetschaal heeft de karakteristiek van onderscheidingsvermogen indien het verschillende getallen aan verschillende waarden van de eigenschap toekent.
Indien grotere getallen een grotere aanwezigheid van de eigenschap weergeven dan is de grootteorde- karakteristiek aanwezig.
Een meeteenheid is aanwezig indien gelijke verschillen tussen getallen eenzelfde verschil in de eigenschap weergeven.
Een meetschaal heeft een absoluut nulpunt wanneer het getal 0 de afwezigheid van de eigenschap weergeeft.
Naargelang de aan- of afwezigheid van deze karakteristieken, onderscheidt men dus vier meetschalen:


Fig. 7 Karakteristieken van meetniveaus#
Een aantal voorbeelden kunnen verhelderend werken. Beschouw daarom even een groep atleten die deelnemen aan een internationale loopwedstrijd. De volgende eigenschappen van de atleten worden gemeten:
Nationaliteit van elke atleet (Nominale schaal)
Deelnemersnummer (= rugnummer) van elke atleet (Nominale schaal)
Aankomst volgnummer van elke atleten (Ordinale schaal)
De lichaamstemperatuur van elke atleet bij aankomst (wanneer uitgedrukt in °C of in °F : Intervalschaal, wanneer uitgedrukt in °K : Ratioschaal)
De gelopen tijd van elk van de atleten (Ratioschaal).
Bepalen van de meetschaal#
Wanneer men geconfronteerd wordt met meetresultaten, zou men de reflex moeten hebben om de meetschaal te bepalen. De eenvoudigste manier om dit te doen, is na te gaan welke van de 4 karakteristieken omtrent de gemeten eigenschap aan- of afwezig zijn. Indien de volgorde: onderscheidingsvermogen, grootteorde, meeteenheid, absoluut nulpunt van de karakteristieken genomen wordt, moet men, vanaf het moment dat een bepaalde karakteristiek niet meer voldoet, de daarna volgende karakteristieken niet meer controleren.
De eerste karakteristiek nl. onderscheidingsvermogen is zo goed als altijd aanwezig wanneer men iets meet. Zo niet heeft het geen zin om te meten.
Voor het vaststellen van de grootteorde-karakteristiek moet men zich de vraag stellen of men de verschillende waarden die de eigenschap kan aannemen, kan ordenen van klein naar groot of van slechtste naar beste en of grotere getallen een grotere aanwezigheid van de eigenschap weergeven. Indien dit niet zo is, zoals bijvoorbeeld voor nationaliteiten, is de eigenschap op nominale schaal gemeten.
Het bestaan van de derde karakteristiek nl. meeteenheid kan men controleren door na te gaan of men een meetinstrument met een geijkte -lineaire- schaal gebruikt heeft voor het meten van de eigenschap. Bij het ontbreken hiervan, is de eigenschap op ordinale schaal gemeten.
Wanneer het getal 0 wijst op de afwezigheid van de eigenschap welke men aan het meten is, is de vierde karakteristiek nl. absoluut nulpunt vervuld. In dit geval kunnen er tussen de mogelijke meetwaarden geen negatieve getallen zitten. Zijn deze negatieve getallen er wel of wijst de nul niet op de afwezigheid van de eigenschap, dan is de eigenschap niet op ratioschaal maar op intervalschaal gemeten.


Fig. 8 Bepalen van de meetschaal#
Aanwezigheid meeteenheid
De aan- of afwezigheid van een meeteenheid blijkt voor veel mensen in de praktijk een moeilijk karakteristiek om na te gaan. Als vuistregel kan je stellen dat er een meeteenheid bestaat, wanneer er een geijkt meettoestel werd gebruikt. Dit wil zeggen dat wanneer twee personen met dit meettoestel dezelfde eigenschap in gelijksoortige omstandigheden meten, ze hetzelfde meetresultaat moeten bekomen. De ijking van het meettoestel dient overeen te komen met een internationaal afgesproken standaard.
Punten gegeven door een jurylid voor de prestaties van een kandidaat op een schoonheid-, dans-, zang- of andere wedstrijd komen niet overeen met een of andere internationale standaard. Er is misschien wel sprake van een soort eenheid waarin het resultaat wordt uitgedrukt nl. ‘het punt’ maar dit is zeker en vast geen meeteenheid.
Aanwezigheid absoluut nulpunt
De aan- of afwezigheid van een absoluut nulpunt lijkt evident en gemakkelijk te controleren, maar toch zitten er soms addertjes onder het gras. In de economie spreekt men van economische groei en van recessie. In feite gaat het hier over dezelfde eigenschap dat wordt gemeten. Wanneer de economie van een land (bruto binnenlands product) in een jaar groter is dan het vorige jaar spreekt men van groei, indien het lager is spreekt men van recessie. Op deze manier splitst men een en dezelfde eigenschap op interval schaal op in twee (verwante) eigenschappen die elk alleen positieve waarden kunnen hebben en waardoor men voor elk een kunstmatig absoluut nulpunt creëert. Dit fenomeen vindt men in de economie op vele plaatsen terug: winst en verlies van een bedrijf, inflatie en deflatie, … Misschien hebben economen schrik van negatieve getallen…
Schaal versus meetschaal
Het is ook niet omdat men soms spreekt van een schaal dat men echt een meeteenheid heeft in de zin zoals hierboven is beschreven.
De schaal van Richter wordt gebruikt om de kracht van aardbevingen weer te geven. Deze schaal relateert de plaatselijke sterkte van de aardbeving aan de logaritme van de maximale amplitude van de schokgolf die wordt geregistreerd (Bron: * Cambridge encyclopedie van de aardwetenschappen*). Wat is de meetschaal in dit geval? Onderscheidingsvermogen en grootteorde zijn twee duidelijk aanwezige karakteristieken. Is er ook een meeteenheid? Daar de schaal van Richter een logaritmische schaal gebruikt, is het verschil tussen 2 en 3 niet even groot als tussen 3 en 4. Het verschil tussen 2 en 3 kan men vergelijken met het verschil tussen 10 en 100 terwijl het verschil tussen 3 en 4 te vergelijken valt met een verschil tussen 100 en 1000. Meetresultaten bekomen met de schaal van Richter zijn dus op ordinale schaal gemeten. Merk op dat microaardbevingen negatieve waarden scoren op de schaal van Richter.
De Beaufortschaal, ingevoerd in 1808, deelt de windsnelheid in 13 klassen in. Sir Francis Beaufort, een Engelse admiraal, ging hierbij uit van het effect van de wind op een volgetuigd oorlogsschip. In onderstaande tabel staat naast de Beaufort-maat ook een andere maat voor windsnelheid nl. snelheid van de wind uitgedrukt in kilometer per uur.
Wat is de meetschaal in dit geval? Onderscheidingsvermogen en grootteorde zijn twee duidelijk aanwezige karakteristieken. Is er ook een meeteenheid? De windsnelheden uitgedrukt in km/h die naast de verschillende mogelijke waarden van de Beaufortschaal staan maken duidelijk dat er geen meeteenheid is en dat men enkel kan en mag spreken van waarden op een ordinale meetschaal.

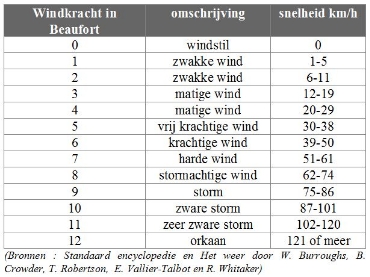
Fig. 9 Windkrachtschaal#
Wat mag en wat mag niet?#
Afhankelijk van de meetschaal mag men al of niet bepaalde wiskundige operaties op de waargenomen waarden toepassen. Dit is te verantwoorden op basis van de karakteristieken die een meetschaal al of niet bezit.


Fig. 10 Toegelaten wiskundige operaties#
Waarden van een eigenschap op bijvoorbeeld intervalschaal mogen bij elkaar worden opgeteld of van elkaar worden afgetrokken. Waarden met elkaar vermenigvuldigen of door elkaar delen mag niet. Wat wel mag is het vermenigvuldigen of delen van de waarden door een constante (= een vast getal).
De toegelaten wiskundige operaties hebben een gevolg en bepalen welke (statistische) verwerkingen men mag toepassen op de data of zoals Stanley Smith Stevens (4/11/1906 – 18/01/1973) -de bedenker van meetschalen- het formuleerde


Fig. 11 Bron : www.azquotes.com/quote/776783#
Het berekenen van bijvoorbeeld het gemiddelde vereist waarden van een eigenschap op interval- of ratioschaal terwijl bijvoorbeeld de mediaan (de middelste waarde wanneer men de waargenomen waarden van klein naar groot op een rij zet) al bepaald mag worden voor waarden op ordinale schaal.
Met gegevens op nominale of ordinale schaal mag niet gerekend worden! Wanneer men dit wel doet, doet men alsof bepaalde niet aanwezige karakteristieken wel aanwezig zijn.
Gegevens op interval- of ratioschaal mogen wel behandeld worden alsof het gegevens zijn op bijvoorbeeld ordinale schaal. Men maakt in dit geval geen gebruik van bepaalde wel aanwezige karakteristieken; het is niet omdat ze er zijn dat men ze moet gebruiken, men mag ze gebruiken.
Wanneer men over meetschalen praat, praat men over getallen die men aan de verschillende mogelijke waarden, die een eigenschap kan aannemen, geeft. Wanneer de waarden van de eigenschap niet numeriek (categorienamen) zijn en men ze gaat vervangen door getallen (categorienummers), dan spreekt men van cardinalisering.
Neem even het geslacht van een persoon als te bestuderen eigenschap. De verschillende mogelijke waarden zijn: * mannelijk* en vrouwelijk. Men kan het getal 0 associëren met de waarde mannelijk en het getal 1 met de waarde * vrouwelijk*. Het toekennen van deze twee getallen is volledig arbitrair. 1 is een groter getal dan 0, maar dat wilt hier niet zeggen dat het vrouwelijke geslacht beter is dan het mannelijke geslacht. Het is niet omdat men nu de verschillende waarden met behulp van getallen (hier 0 en 1) voorstelt, dat men de karakteristieken van de eigenschap mag vergeten en beginnen te rekenen met deze getallen. Wie dit negeert, kan absurde dingen gaan berekenen zoals bijvoorbeeld het gemiddeld geslacht van een groep mensen!
Ook voor het weergeven van het opleidingsniveau van een persoon associeert men getallen met de verschillende waarden. Bijvoorbeeld: 1 voor lager onderwijs; 2 voor lager secondair onderwijs; 3 voor hoger secundair onderwijs; * 4* voor hoger onderwijs niet universitair; 5 voor universitair onderwijs. Deze getallen zijn arbitrair toegekend, en het verschil tussen deze getallen heeft geen betekenis. Het verschil tussen 1 en 2 is niet hetzelfde als het verschil tussen 4 en 5. Men kan niet beweren dat het verschil tussen het lager onderwijs en het lager secondair onderwijs even groot is als het verschil tussen hoger niet universitair onderwijs en universitair onderwijs. Kortom, met deze getallen mag niet gerekend worden.
Wie denkt dat niemand de fout maakt om te gaan rekenen met de waarden van de bovenvermelde eigenschappen van personen, komt bedrogen uit.
Discriminantanalyse is een techniek waarbij men berekeningen maakt met waargenomen waarden van meerdere eigenschappen van bijvoorbeeld dezelfde personen. Deze techniek wordt veel gebruikt in de bankwereld en ondanks het feit dat men niet met waarden van eigenschappen op nominale of ordinale schaal mag rekenen, vindt men tussen de gebruikte eigenschappen zeer regelmatig eigenschappen zoals geslacht, opleidingsniveau,… terug.
Eigenschappen op nominale of ordinale schaal kunnen gebruikt worden om deelpopulaties te bepalen, waarna men de discriminantanalyse per deelpopulatie op de andere eigenschappen kan loslaten.
Ook op het domein van de multicriteria-analyse (daar probeert men een keuze te maken tussen verschillende alternatieven rekening houdend met meerdere doelstellingen) worden in zeer veel methoden eigenschappen op ordinale schaal behandeld alsof het eigenschappen op ratioschaal zijn. Multicriteriamethoden die eigenlijk alleen maar mogen gebruikt worden wanneer alle eigenschappen op ratioschaal gemeten zijn, worden gebruikt om bij de aanwerving van een werknemer of de promotie van een medewerker een keuze te maken tussen meerdere kandidaten. Onder de eigenschappen van de kandidaten zijn er steeds een aantal die enkel op ordinale of nominale schaal zijn gemeten.
Meetniveaus of meetschalen vormen de basis voor een goed en correct begrip van meten en het correct interpreteren van meetresultaten en verwerkingen van meetresultaten.
Discrete en continue variabelen#
Wanneer men een meting verricht, wordt een waarde toegekend als weerspiegeling van de mate waarin de te meten eigenschap aanwezig is (zie I.2). Gemeten waarden op een interval of ratioschaal worden uitgedrukt aan de hand van getallen. Het getal duidt aan hoeveel keer de meeteenheid werd vastgesteld tijdens de meting. Wanneer de meeteenheid niet in onderdelen kan verdeeld worden zoals bijvoorbeeld het aantal virtuele servers die op een fysieke host server werden geconfigureerd, het aantal files met een bepaalde file extensie die op een harde schijf staan, … is het resultaat van de meting steeds een gehele waarde. De meetresultaten kunnen dus enkel spronggewijs toenemen: ofwel zijn er 13 virtuele servers geconfigureerd ofwel 14. Een waarde tussen 13 en 14 zoals bv. 13,47 servers, is niet mogelijk. Indien het verschil tussen twee gemeten waarden steeds een of meerdere eenheden dient te bedragen, spreekt men van een discrete vriabele.
Wanneer de meeteenheid wel in onderdelen kan verdeeld worden zoals bijvoorbeeld de tijd nodig om een script uit te voeren (in seconden) op een server, … is het resultaat van de meting een decimale waarde (het aantal cijfers na de komma is afhankelijk van de gewenste precisie en van de nauwkeurigheid van het gebruikte meetinstrument). Een uitvoertijd van 3.597 seconden voor een bepaald script is een mogelijk meetresultaat. Indien het verschil tussen twee gemeten waarden ook in een fractie van de meeteenheid kan worden uitgedrukt, spreekt men van een continue variabele.
Betrouwbaarheid en validiteit van data#
Heel wat data wordt bekomen door middel van metingen. Maar aan welke criteria dient een meting te voldoen om te kunnen spreken van een goede meting? Op de eerste plaats dienen we te kijken naar het waarom van de meting, wat is het doel van de meting? Het ligt voor de hand dat een goede meting beantwoord aan het doel van de meting. Om een meting te bekomen gebruikt men een meetinstrument. Hierbij denken we bijvoorbeeld aan een weegschaal om het gewicht van een persoon of voorwerp te bepalen. Maar een examen is ook een meetinstrument. Hierbij wordt ‘gemeten’ in welke mate een student de beoogde doelstellingen van het vak heeft bereikt. Voor het bepalen van het gewicht van een persoon kunnen we ons niet direct een ander meetinstrument voorstellen dan een weegschaal. Om te meten of een student de beoogde doelstellingen van het vak heeft bereikt kan in plaats van een examen gedacht worden aan bijvoorbeeld een eindwerk in de vorm van een beroepsproduct of bijvoorbeeld aan een vorm van permanente evaluatie tijdens de lessen.
Als er meerdere meetinstrumenten zijn om hetzelfde te meten rijst de vraag of al deze verschillende meetinstrumenten tot hetzelfde resultaat zullen leiden. Indien niet, welke zou je dan het best gebruiken?
Er zijn twee belangrijke eisen die men aan een meetinstrument kan stellen:
Betrouwbaarheid: levert het meetinstrument onder identieke omstandigheden dezelfde waarden op? In de praktijk blijken niet alle metingen even betrouwbaar. Zo kan het aantal punten op een examen verschillen bij studenten met dezelfde kennis en vaardigheden of kunnen lengtemetingen afwijken wanneer de metingen door verschillende personen worden uitgevoerd die niet op dezelfde manier te werk gaan. Wanneer de invloed van toevallige factoren geen groot verschil geeft in de resultaten, spreekt men van een betrouwbaar meetinstrument. Onder gelijkblijvende omstandigheden moet een betrouwbaar meetinstrument hetzelfde resultaat opleveren.
Validiteit: meet het meetinstrument wel wat het beweert te meten? M.a.w.: wat betekenen de scores, wat is de bruikbaarheid ervan en wat is de juistheid van de conclusies gebaseerd op deze scores? Een meetinstrument is valide als het meet wat het moet meten en als een andere meetwijze hetzelfde resultaat zou opleveren. Een niet-valide meetinstrument maakt systematische fouten zoals bijvoorbeeld een weegschaal die verkeerd is afgesteld of een test die in bepaalde (moeilijke) omstandigheden wordt afgenomen. Als je bijvoorbeeld de kwaliteit van een service meet aan de hand van de tevredenheid, dan is dat misschien niet valide daar er nog andere favtoren kunnen meespelen in de tevredenheid naast de kwaliteit.
Wanneer een meetinstrument betrouwbaar is, wil dat nog niet zeggen dat het ook een valide meetinstrument is.


Fig. 12 Samenspel betrouwbaarheid en validiteit#
Hoe informatie uit data halen?#
Data kan beschouwd worden als stukjes informatie, maar niet als informatie. Pas wanneer data op zo een wijze verwerkt, geïnterpreteerd, georganiseerd, gestructureerd of gepresenteerd wordt dat het bruikbaar of betekenisvol wordt, spreekt men van informatie.
Vereenvoudigd gesteld, dient er eerst betekenis aan data te worden toegevoegd vooraleer het informatie wordt. De datum 2 november zegt op zich niet veel, tot de betekenis, namelijk de verjaardag van een vriend, eraan toegevoegd wordt.
Waarnemingen zoals bijvoorbeeld de gemiddelde jaartemperatuur gemeten te Ukkel (van 1933 tot 2016) vormt data. De vaststelling dat de gemiddelde jaarlijkse temperatuur in deze periode is gestegen is informatie.


Fig. 13 Evolutie van de gemiddelde temperatuur te Ukkel tussen 1833 en 2016(Bron: KMI)#
Belangrijk om te weten voor een data scientist: Computers need data, humans need information. M.a.w. data wordt met behulp van computers omgevormd tot informatie, bruikbaar voor mensen. Wat mensen met deze informatie doen is een andere vraag waar o.a. de DIKW-pyramide een antwoord op kan geven.


Fig. 14 Een DIKW piramide#
Er bestaan verschillende disciplines en technieken om vertrekkende van data te komen tot informatie.
Klassiek (statistisch) onderzoek#
Bij een “klassiek” onderzoek kunnen we verschillende onderzoeksfasen onderscheiden (zie van Peet et al [4]):
fase 1: formuleren van vraagstelling, probleem, theorie
fase 2: meetbaar maken, operationaliseren
fase 3: steekproefopzet
fase 4: verrichten van metingen, verzamelen van gegevens
fase 5: beschrijven van gegevens
fase 6: formuleren van statische conclusies
fase 7: verband tussen resultaten en theorie
Laten we deze fasen even verduidelijken aan de hand van een voorbeeld. Binnen de informatica-wereld wordt er al snel beweerd dat Linux servers beter bestand zijn tegen cyberaanvallen dan Windows servers. Men kan zich de vraag stellen of dit wel zo is. Om hierop een antwoord te vinden kunnen we de bovenvermelde onderzoeksfasen gebruiken.
Fase 1: formuleren van vraagstelling, probleem, theorie
Een onderzoek start steeds met een onderzoeksvraag, de vraag waarop met behulp van het onderzoek een antwoord dient te worden geformuleerd. In ons voorbeeld kunnen we de onderzoeksvraag als volgt formuleren: Zijn Linux servers beter bestand tegen cyberaanvallen dan Windows servers?
Een onderzoeksvraag wordt tijdens deze fase eveneens geherformuleerd in een onderzoekshypothese. Dit is in de vorm van een antwoord op de onderzoeksvraag. De bedoeling is nu om tijdens het verder onderzoek, op basis van een analyse op de verzamelde gegevens, na te gaan of deze geformuleerde onderzoekshypothese wel houdbaar is. In ons voorbeeld kunnen we de onderzoekshypothese als volgt formuleren: Windows-servers zijn beter bestand tegen cyberaanvallen dan Linux-servers?
Het is de bedoeling dat zowel de onderzoeksvraag als de onderzoekshypothese geformuleerd worden in termen van meetbare kenmerken van de objecten (of personen) beschouwd in het onderzoek. In ons voorbeeld zijn de objecten in het onderzoek servers en één van de kenmerken die tijdens het onderzoek zal bekeken worden is het operating system dat op elke server staat. Een kenmerk van een object dat verschillende waarden kan hebben, noemt men ook een variabele.
In een goed gestelde onderzoeksvraag (en ook in een goed gestelde onderzoekshypothese) komen twee variabelen voor. De eerste variabele geeft de oorzaak weer (in ons voorbeeld, het operating system) en de tweede variabele geeft het gevolg weer (in ons voorbeeld, het bestand zijn tegen virussen). De tweede variabele (gevolg) wordt ook wel de afhankelijke variabele genoemd omdat de waarden van deze variabele volgens de onderzoekshypothese afhankelijk zijn van de waarden op de eerste variabele. De eerste variabele (oorzaak) wordt ook wel de onafhankelijke variabele genoemd. In het verder onderzoek willen we nagaan of de onafhankelijke variabele effectief een invloed heeft op de afhankelijke variabele.
Naast variabelen kunnen er ook constanten voorkomen in een onderzoekshypothese. Een constante heeft steeds dezelfde waarde binnen dit onderzoek en geeft in feite informatie over de omstandigheden waarin het onderzoek gebeurt.
Voorbeeld van variabelen en constanten in een onderzoekshypothese:
Onderzoekshypothese: In het schooljaar 2012-2013 hebben 10-jarige jongens meer aanleg voor wiskunde dan 10-jarige meisjes
Variabelen: geslacht (onafhankelijke variabele), aanleg voor wiskunde (afhankelijke variabele)
Constanten: schooljaar, leeftijd
Fase 2: meetbaar maken, operationaliseren
Om de onderzoekshypothese op zijn juistheid te kunnen testen, dienen de gebruikte begrippen in deze onderzoekshypothese meetbaar gemaakt te worden. M.a.w. er dient precies te worden aangegeven hoe de verschillende waarden van de begrippen kunnen worden vastgesteld. Dit noemt men het operationaliseren van de begrippen.
Al we dit toepassen op ons voorbeeld, moeten we de begrippen ‘Linux server’, ‘Windows server’ en ‘cyberaanvallen’ operationaliseren:
Linux-server: welke distributie, versie, hardware, applicaties, …?
Windows-server: welke versie, firewall, virusscanner, applicaties, …?
Cyberaanvallen: virussen, trojans, DOS attacks, fishing, XSS, …?
Merk op, dat bij het operationaliseren van de begrippen keuzes moeten worden gemaakt.
Fase 3: steekproefopzet
Nu we weten wat we onderzoeken en hoe we de variabelen kunnen meten, kunnen we nadenken over het verzamelen van de gegevens. Hierbij botsen we op een probleem: we kunnen onmogelijk alle bestaande servers wereldwijd (= populatie) uittesten. Daar ontbreekt o.a. de tijd en de middelen voor. Bovendien verandert de wereldwijde populatie van servers voortdurend (elk dag of zelfs uur zullen er wel ergens in de wereld nieuwe servers in dienst worden genomen en/of oude servers buiten dienst worden gesteld). Wanneer niet de volledige populatie kan onderzocht worden, zullen we ons moeten beperken tot een testgroep (= steekproef, het deel van de populatie dat daadwerkelijk wordt onderzocht).


Fig. 15 Steekproef uit een populatie trekken#
We gaan dus onze metingen uitvoeren op deze steekproef, wat de vraag doet rijzen of we de resultaten van de steekproef wel mogen veralgemenen (= een uitspraak doen over de gehele populatie)? Hiervoor dienen twee aspecten van een steekproef in acht te worden genomen:
Maak gebruik van een “aselecte steekproef”. Hierbij worden de objecten uit de populatie via ‘toeval’ geselecteerd en elk element in de populatie heeft dezelfde kans om in de steekproef terecht te komen. Het generaliseren van de resultaten van een aselecte steekproef is meestal betrouwbaarder dan het generaliseren van de resultaten van een niet-aselecte steekproef.
Hoe groter de steekproef, hoe betrouwbaarder de resultaten.
In deze fase wordt dus concreet bepaald hoe de steekproef wordt samengesteld en hoe groot deze steekproef zal zijn.
Fase 4: verrichten van metingen, verzamelen van gegevens
Voor het verzamelen van gegevens of het verrichten van metingen bestaan er verschillende, –bekende- methoden zoals o.a. interviews, observaties, vragenlijsten, experimenten, test/ toets/ proefwerk, archiefonderzoek,..
Afhankelijk van de aard van het onderzoek en de aard van de te verzamelen gegevens en/of te maken metingen, selecteert men één of meerdere van deze methoden en past men ze toe om op het einde van deze fase te komen tot een verzameling van ruwe gegevens. Ruw duidt hier op het feit dat er nog geen bewerkingen op de gegevens werden uitgevoerd.
Fase 5: beschrijven van gegevens
De gegevens worden eerst en vooral op een statistische manier beschreven. ‘Beschrijven’ duidt hier op het op een informatieve wijze weergeven van de gegevens zonder het trekken van conclusies. Hierbij wordt beroep gedaan op elementen en technieken uit de beschrijvende statistiek zoals o.a. de frequentietabel, het diagram, het gemiddelde, de mediaan, de correlatie, de regressie,…
Fase 6: formuleren van statische conclusies
Aan de hand van de toetsende statistiek proberen we een antwoord te vinden op de vraag: in hoeverre zijn de resultaten die we in de steekproef gevonden hebben ook van toepassing op de gehele populatie? M.a.w. in hoeverre is de onderzoekshypothese waar?
De steekproefgrootte en de spreiding van de gemeten resultaten uit de steekproef spelen hierbij een niet te onderschatten rol.
Fase 7: verband tussen resultaten en hypothese
Nadat de statistische conclusies werden geformuleerd, moeten de resultaten nog in verband worden gebracht met de hypothese. Concreet worden de resultaten geïnterpreteerd en gevalideerd zodat een uitspraak over de hypothese kan worden gemaakt. Meestal wordt gesteld dat de onderzoekshypothese al of niet kan worden verworpen. Hier kan ook beslist worden om de onderzoekshypothese bij te stellen en dat bijkomend onderzoek nodig is.
Wees kritisch want soms leidt onderzoek –zelfs wanneer de boven vermelde fasen worden gehanteerd- tot foute interpretaties. Enkele van de meest voorkomende redenen van foute interpretaties zijn:
Heel wat statistieken worden gemaakt op vraag (in de hoop dat een bepaald resultaat behaald wordt)
Resultaten worden verkeerd doorgegeven (mutant stats) vb: 58% ligt halverwege tussen 50% en 66%. Het percentage kan dus omschreven worden als “meer dan de helft” maar ook als “bijna 2/3”
Soms is er toeval in het spel
Mensen geloven elkaar
Business Intelligence (BI)#
Business Intelligence stelt een model op om specifieke gekende businessvragen te kunnen beantwoorden. Hierbij maakt BI gebruik van vooraf vastgelegde structured data voornamelijk beschikbaar in data warehouse omgevingen. BI doet beroep op OLAP (OnLine Analytical Processing) technieken om dashboards, rapporten enz. te genereren om de specifieke voor gedefinieerde business vragen te beantwoorden.


Fig. 16 Typische BI-georiënteerde organisatie van bedrijfsdata#
Data Analytics#
Data Analytics stelt een model op op basis van een ‘deep dive’ in grote hoeveelheden beschikbare, verzamelde en voorbereide data (= smart data). Men weet op voorhand niet precies waar men naar op zoek is, maar men staat open voor nieuwe inzichten.
Er bestaan verschillende vormen van data analytics. Een aantal firma’s die data analytics-diensten aanbieden zoals o.a. Gatner en Deloitte hebben een aantal van deze vormen in een Maturity Model samengebracht.


Fig. 17 Data Analytics Maturity Model volgens Gartner#


Fig. 18 Talent Analytics Maturity Model van Deloitte#
Data analytics moet gezien worden als een aanvulling op Business Intelligence (niet ter vervanging van).
Predicitive Analytics is een deel domein van Data Analytics (zie figuren I.5.4 en I.5.5) waarbij een voorspelend model wordt bekomen.
Data analytics doet beroep op o.a. data mining en A.I. (machine learning) maar ook op statistiek om inzichten, relaties en verbanden in de grote hoeveelheden data te ontdekken die relevant zijn voor de business.
Analyseren van data:
Data mining betreft voornamelijk het zoeken van bruikbare patronen, verbanden en associaties in data door data te beschrijven, samen te vatten, te groeperen, enz.
Machine learning:* Hier ‘leert’ een computer programma uit de aangeboden data en past het geleerde toe op nieuwe data.
Statistiek betreft het verzamelen, bewerken, interpreteren en presenteren van gegevens. Een deel van de statistiek spitst zich toe om op basis van waarnemingen van (soms) beperkte hoeveelheden gegevens over een populatie (m.a.w. een steekproef) informatie te verkrijgen over deze populatie.
Data Science Processes#
Wat is Data Science?#
Er werden al heel veel ‘Data Science’-boeken geschreven en er zullen er ongetwijfeld nog heel veel volgen. In een groot deel van deze boeken wordt Data Science gepresenteerd als zijnde een verzameling van statistische methoden en software tools plus de kennis om ze te kunnen gebruiken. Data Science wordt door anderen dan weer gezien als een geheel van processen en concepten die als ondersteuning en leidraad gebruikt kunnen worden om beslissingen te nemen in de context van data-driven projecten.
Methoden, tools en kennis om ze toe te passen zijn effectief nodig, maar op zichzelf onvoldoende. Begrijpen wanneer, hoe en waarom een tool of methode kan (en mag) toegepast worden is even belangrijk. In deze tekst nemen we dan ook het standpunt in dat beide visies, die eerder complementair dan tegenstrijdig zijn, kunnen samengaan en bovendien een beter beeld geven van wat Data Science inhoudt.
Data Science vs. Statistics vs AI vs … .#
‘Data Science’ is een jong interdisciplinair vakgebied dat zijn oorsprong vindt in een aantal andere ‘oudere’ vakgebieden. Meestal wordt er verwezen naar het vakgebied ‘Statistiek’ en naar het vakgebied ‘Computer Wetenschappen’ ( o.a. de deelvakgebieden ‘Data Mining’ en ‘AI - Machine Learning’) maar Data Science is ook schatplichtig aan het vakgebied ‘Operationeel Onderzoek’ (o.a. het deelvakgebied ‘Decision Theory’) en het vakgebied ‘Wiskunde’.

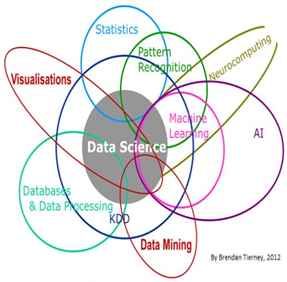
Fig. 19 Het multidiciplinair karakter van het vakdomein Data Science#
Wat doet een data scientist (en wat doet hij niet)?#
Regelmatig wordt een data scientist vergeleken met een software ontwikkelaar (of software engineer). Zowel de softwareontwikkelaar als de data scientist is vertrouwd met meerdere verschillende tools en frameworks voor het bouwen van informatie systemen. De softwareontwikkelaar werkt echter voornamelijk met duidelijke en logische componenten (vb. if A then B) terwijl een data scientist eerder werkt met probabilistische componenten (vb. if A then probably B) m.b.t. data en resultaten.
Een data scientist zal een groot deel van zijn tijd (80%) besteden om vertrekkende van (big) data, afkomstig uit een grote verscheidenheid van bronnen en opgeslagen in verschillende formaten, te komen tot smart data. Het bepalen van welke verwerkingen er nodig zijn en kunnen toegepast worden op de smart data, de verwerking zelf en de interpretatie van de resultaten van de verwerkingen nemen een kleiner deel in beslag van de tijd van de data scientist (20%).
Van een data scientist worden soms wonderen verwacht. Een data scientist levert wel een toegevoegde waarde, maar kan niet toveren. Data met een lage betrouwbaarheid, kan door een data scientist niet omgezet worden in data met een hoge betrouwbaarheid.
De levenscyclus van een ‘Data Science’-project#
Meestal werkt een data scientist aan data-centric projecten. De levenscyclus van een ‘Data Science’-project kan opgedeeld worden in drie fasen:
Fase 1 - Prepare: In deze voorbereidende fase
worden de doelstellingen bepaald [Set goals];
wordt via een exploratie de benodigde data geïdentificeerd evenals uit welke omgevingen deze data moet komen [Explore];
wordt de data gemanipuleerd en gekneed (Data Enrichment ook wel Data Cleaning en soms ook Data Wangling, Data Reshaping of Data Munging genoemd) tot bruikbare smart data [Wrangle];
wordt er een data assessment uitgevoerd. Hierbij worden o.a. technieken uit de beschrijvende statistiek gebruikt om de data beter te ‘bevatten’, worden veronderstellingen m.b.t. de data gecontroleerd en worden er korte en ruwe data-analyses gemaakt om de data beter te ‘begrijpen’ [Assess].
Fase 2 – Build: In deze fase
wordt er een plan opgesteld om de gestelde doelen te bereiken, gebaseerd op wat werd geleerd tijdens de exploratie en assessment stappen van de vorige fase [Plan];
wordt bepaald welke de benodigde data analyses zijn die moeten worden uitgevoerd [Analyze];
worden de benodigde statistische software tools en programmeer platforms geïdentificeerd en vastgelegd [Engineer];
worden eventuele andere benodigde of nuttige software tools vastgelegd [Optimize];
wordt het plan uitgevoerd [Execute].
Fase 3- Finish: In deze fase
wordt het product opgeleverd in een door de klant gevraagd en/of voor een klant geschikte vorm [Deliver];
wordt het product herbekeken en waar nodig bijgestuurd op basis van de feedback van de klant [Revise];
worden de laatste bugs weggewerkt, de documentatie afgewerkt, de transitie naar operations afgerond en een post mortem evaluatie van het project met de ‘lessons learned’ wordt uitgevoerd [Wrap up];


Fig. 20 Het ‘Data Science’-Project#
Data Science Pipeline#
In de levenscyclus van een ‘Data Science’-project wordt het proces van data transformatie naar inzichten en data producten als een straight-forward proces weergegeven. In heel wat concrete situaties is dit ook zo en kan deze benadering toegepast worden. Daarnaast zijn er ook situaties waar dit ‘data transformatie’-proces gezien moet worden als een iteratief proces waarbij het voortschrijdend inzicht een belangrijke rol speelt. Deze iteratieve benadering wordt omschreven met de term ‘Data Science Pipeline’ en is een complex proces bestaande uit een aantal onderling afhankelijke deelprocessen. Elke deelproces kan je dichter bij het eindresultaat brengen, maar kan je ook de noodzaak doen inzien om terug te gaan naar een vorig deelproces. Wij onderscheiden 4 deelprocessen in de Data Science Pipeline namelijk Collecting Data, Data Engineering, Data Modeling en Information Distilation. Merk op dat in andere weergaves van de ‘Data Science Pipeline’ het deelproces Collecting Data soms als een onderdeel van het deelproces Data Engineering wordt beschouwd. Om het belang ervan te onderstrepen kiezen we er in deze tekst ervoor om Collecting Data als een afzonderlijk deelproces te beschouwen.


Fig. 21 Data Science Pipeline#
Collecting Data#
In dit deelproces wordt de data verzameld. Het klinkt eenvoudig, maar het succes van het uiteindelijke /data model of data product hangt sterk af van het feit of al dan niet voldoende geschikte data kan gevonden worden. De geschikte data sources identificeren is cruciaal en verloopt in een 3-tal stappen:
Hunting: Hierbij wordt een antwoord gezocht op de vraag: wie beschikt over de benodigde data en hoe kan ik deze bekomen? Hierbij wordt niet alleen gekeken naar intern in de organisatie beschikbare data, maar ook externe data. Sommige bedrijven (zoals bv The New York Times, Twitter, Facebook en Google) stellen beperkt data ter beschikking (via API’s) evenals sommige overheidsinstellingen en universiteiten. Daarnaast zijn er ook open data resources via internet te vinden.
Scraping: Op websites kan me heel wat interessante en nuttige data terugvinden. Met behulp van spiders en scrapers kan men deze data uit de webpagina’s halen om daarna in analyses te gaan gebruiken. Op sites zoals SourceForge en Github kan je spiders en scrapers vinden voor populaire websites. Je hoeft ze dus niet altijd zelf te gaan programmeren. Logging: Wanneer je zelf beschikt over een data source (bv.webserver, communication device, location device,..) verzamel dan data via loggings. Vroeg of laat komt het van pas. Zeker wanneer op een bepaald moment deze logging data kan gecombineerd worden met data komende van andere bronnen.
Data Engineering#
In dit deelproces wordt de data klaar gemaakt zodat in latere stappen er analyses kunnen worden op uitgevoerd. Hierbij kunnen 3 stappen onderscheiden worden:
Data Preparation: het doel van deze stap is om de data klaar te maken zodat het kan worden geëxploreerd. Hierbij worden outliers gedetecteerd en indien nodig verwijderd of afgevlakt; wordt de data indien nodig of vereist genormaliseerd en wordt de data in een data structuur (meestal een data frame) geplaatst. Het belangrijkste aspect van deze stap is dat alle data op één plaats wordt samengebracht in een vorm dat verdere verwerking toelaat.
Data Exploration: In deze stap worden heel wat data visualisaties (o.a. plots) en beschrijvende statistieken op de data toegepast voornamelijk met als doel een beter begrip en inzicht te verwerven van de data. Ook worden er hier statistische analyses op de data toegepast om eventuele veronderstelling m.b.t. de data te testen.
Data Representation: Hier wordt de data in de meest geschikte data structuren (gebruik makende van de meest geschikte data types) gestoken om zowel de opslag als de (latere) verwerking van de data te optimaliseren.
Data Modeling#
In dit deelproces dient de data te worden omgezet in een voorspelling (predictive analytics) of een (nieuw) inzicht. In de praktijk wordt er hier geëxperimenteerd met niet één maar met meerdere modellen. Daarna worden de experimenten geëvalueerd op basis van performantie-metrieken. Uiteindelijk komt men tot één robuust model dat op zich eventueel een combinatie of samensmelten is van meerdere modellen.
Hierbij kunnen 2 stappen onderscheiden worden:
Data Discovery: In deze stap gaat men op zoek naar patronen en potentiële inzichten en bouwt men de fundamenten van het model. Ook worden in deze stap hypotheses geformuleerd en getest. Het is de bedoeling om diep in de data te duiken en de ‘low hanging fruit’-inzichten te verwerven vooraleer meer robuuste modellen te gaan uitwerken (zie volgende stap).
Data Learning: In deze stap wordt een robuust model gecreëerd gebaseerd op de verworven inzichten uit de vorige stap en wordt het model op een betrouwbare manier getest. In het model dat hier gecreëerd wordt, wordt in de meeste gevallen een mapping van de input variabelen naar de output variabele uitgevoerd (predictief model) of wordt er een structuur opgebouwd. Afhankelijk van het model zal hier de data worden opgesplitst in een training data set en een testing data set.
Information Distilation#
In dit deelproces wordt alles uit de vorige deelprocessen samengebracht, samengevat en aan de ‘klant’ gepresenteerd.
Hierbij kunnen 2 stappen onderscheiden worden:
Data Product Creation: In deze stap wordt het uiteindelijke data model of data product gecreëerd. Hierbij wordt via een user interface (meestal een web browser) toegang verleend tot het (al getrainde) data model of data product dat zich op een backend systeem bevindt. De gebruiker zal in de praktijk het systeem gaan gebruiken als een ‘black box’ – invoer van gegevens zal een resultaat opleveren, zonder dat de gebruiker weet of beseft wat er in het data model of data product allemaal gebeurd om vertrekkende van de input te komen tot de output-.
Insight, deliverance and visualization: In deze stap worden de belangrijkste bevindingen van de analyses samengevat in een interessant, inzicht verschaffend en werkbaar geheel. De officiële oplevering van het eindresultaat (data model of data product) aan de klant / opdrachtgever vindt plaats. Daarnaast kan ook een visuele weergave van de prestaties van het opgeleverde data model of data product worden opgesteld en beschikbaar gesteld.
Het is belangrijk om nogmaals te onderlijnen dat tijdens de uitvoering van een data science pipeline proces de deelprocessen en stappen niet altijd de een na de ander worden uitgevoerd. Door onverwachte resultaten of situaties, inzichten, … is het soms noodzakelijk om terug te keren naar een vroegere stap of deelproces.
Data Science-methodologieën en -technieken#
Zowel in de Data Science-project als in de Data Science Pipeline aanpak worden er in de verschillende stappen heel wat technieken en methoden gebruikt. Dit hoofdstuk geeft een overzicht van veel gebruikte methodologieën en technieken. Om het overzichtelijk te houden werden de methodologieën en technieken ingedeeld in een negental groepen.
Statistische technieken
Beschrijvende statistiek
Kansrekenen
Statistische analyse
Predictive Analytics
Classification
Regression
Time-series Analysis
Anomaly Detection
Text Prediction
Component Analysis
Principal Component Analysis
Independent Component Analysis
Recommender Systems
Content-based Systems
Collaborative Filtering
Non-negative Matrix Factorization (NMF or NNMF)
Automated Data Exploration Methods
Data Mining
Association Rules
Clustering
Graph Analytics
Dimensionless Space
Graph Algorithms
Other Graph-related Topics
Natural Language Processing (NLP)
Sentiment Analysis
Topic Extraction/Modeling
Text Summarization
Other NLP Methods
Artificial Intelligence
Machine learning
Neural networks
Deep Learning
Artificial Creativity
Other AI-based Methods
Other Methodologies
Chatbots
Data Scientist’s Toolbox#
Om de technieken en methoden die gebruikt worden in zowel de ‘Data Science’-project als in de’ Data Science Pipeline’-aanpak uit te voeren heeft een data scientist tools nodig. In dit hoofdstuk wordt een overzicht van veel gebruikte tools gegeven. Om het overzichtelijk te houden werden de tools ingedeeld in een zestal groepen.
Database Platforms
SQL-based Databases
NoSQL Databases
Graph-based Databases
Programmeertalen voor Data Science
R
Julia
Python
Scala
Other Data Analytics Software
MATLAB
Analytica
Mathematica
Visualization Software
D3.js
WolframAlpha
Tableau
Data Governance Software
Spark
Hadoop
Storm
Version Control Systems (VCS)
Git
Github
CVS
Bibliografie
[1] Godsey, Brian (2017):Think Like a Data Scientist - Tackle the data science process step-by-step, Manning Publications, ISBN 978-1-633-43027-3
[2] Reese, Richard M.; Reese, Jennifer L. and Grigorev Alexey (2017): Java Data Science Made Easy, Packt Publishing, ISBN 978-1-78847-565-5
[3] Skiena, Steven S. (2017): The Data Science Design Manual, Springer International Publishing, ISBN 978-3-319-55443-3
[4] van Peet, A., Namesnik, K. and Hox, J. (2010): Toegepaste Statistiek. Beschrijvende Technieken Noordhoff Uitgevers, ISBN 978-90-01-80243-1
[5] Voulgaris, Zacharias (2017): Data Science Mindset, Methodologies, and Misconceptions, Technics Publications, ISBN 978-1-634-62256-1 19